(논문리뷰) CRAFT (Character Region Awarenness for Text Detection)

최근에 Scene text detection은 Neural Network를 기반으로 한 방법이 급상승하고 있다. 이전 논문들은 엄격한 word-level로 박스를 만드는 것이 때문에 임의의 모양으로 있는 text 영역을 표현하기에는 어려웠다. 본 논문에서는, character 각각과 각 character 사이의 affinity을 탐구함으로써 텍스트 영역을 효과적으로 검출할 수 있는 new scene text detection 방법을 제안한다. 결국 chr들을 잘 잡은 다음에, 다시 잘 word로 바꿔주는 것 같다. 각각의 character level annotation의 부족을 극복하기 위해, 제안된 프레임워크는 2가지다.
- 합성 이미지에 대해 주어진 Character level annotation
- 실제 이미지로 estimated된 character-level ground-truths ⇒ character-level ground truths는 학습된 중간 모델에 의해 획득되었다.
1. Introduction
현재 Scene text detection에 대해서 많은 관심이 있다.
- instant translation
- image retrieval
- scene parsing
- geo-location
- blind-navigation
위에서 말한 것들은 요즘 딥러닝이 발전하면서 좋은 성능을 내고 있다. 하지만 이런 것들은 현재 word level bounding box로 국한시켜서 훈련시킨다. 이러다 보니, 아래와 같은 text들을 single bounding box로 탐지하기는 어렵다.
- curved text
- deformed text
- extremely long text
만약 위의 text들을 character-level로 인식하고, 이후 bottom-up 방법으로 연속적인 Character를 연결하는 것은 많은 장점이 있다고 한다. 하지만 이러한 character-level annotation은 존재하지 않고, character-level gound truth를 만드는 작업은 비용이 많이든다. 이 논문에선, 개별 character 영역을 국한하는 새로운 text detector 와 detected 된 characters를 하나의 text instance로 연결하는 방법에 대해서 제안한다다. 여기서는 CRAFT ( Character Region Awareness For Text detection) 것이 있는데, 그것은 character region score와 affinity score를 만드는 CNN이라고 한다.
Region Score
- 이미지에서 개별 characters를 국한하는 데 사용
affinity Score
- 각각의 character를 하나의 instance로 그룹을 해줄 때 사용
위에서 말한 character 수준의 annotation의 부족을 보충하기 위해, 실제 word level 데이터셋에서 존재하는 character level ground truths를 추정하는 weakly supervised learning을 제안한다. 즉 self training을 통해서 비용절감, 인력 낭비를 줄인다. 사용한 데이터로는 ICDAR ( validation 하기 위한 용) MSRATD500, CTW-1500 TotalText datasets (long, curved, arbitrarily shape text 같이 어려운 경우가 많은 것들)을 통해서 제안한 모델의 신뢰성을 보여준다.
2. Related Work
Regression-based text detectors
텍스트 같은 경우 불규칙한 모양을 가지고 있기 때문에, 이러한 문제를 해결하기 위해 TextBoxes는 다양한 텍스트 모양을 효과적으로 캡처할 수 있도록 복잡한 커널과 앵커 박스를 수정했다. **DMPNet(=Deep matching prior network)**은 4각 슬라이딩 윈도를 통합하여 문제를 더욱 줄이려고 노력했다. 최근에는 Rotation-Sensitive Regression Detector(RSDD) convolution filter를 능동적으로 회전시키면서 회전 불변성 한 feature를 완전히 사용하는 방법이 제안되기도 했다. 하지만 이러한 방법론들은 가능한 shape를 포착하는데 구조적 한계가 있다.
Segmentation-based text detectors
픽셀 단위에서 텍스트 영역을 찾기 위한 방법론이다. word bounding area를 추정함으로써, text를 찾는 방법론은 (Multi-Scale FCN , Holistic-prediction, PixelLink) 이 제안됐다. SSTD는 feature level에서 배경 간섭을 줄임으로써, text 관련 영역을 향상하는 attention mechanism을 사용하여 regression과 segmentation 둘 다 로부터 장점을 얻으려고 노력했다. 최근에는 TextSnake 기하학적인 특정과 함께 중안 선과 text 영역을 예측함으로써, text 객체를 탐지하는 것을 제안하기도 했다.
End-to-end text detectors
이 방법론은 인식 결과를 leveraging 함으로써, detection 정확도를 향상하려는 detection과 recognition 모듈을 동시에 학습하려는 방법론이다. FOTS , EAA / MASK TextSpotter
Character-level text detectors
이 논문은 Character 수준 detector를 훈련시키는 Weakly supervised framework를 사용하는 Wordsup에서 영감을 받았다고 한다. 그러나 WordSup의 단점은 character representation이 사각형 anchors로 형성된다. 이러한 것은 다양한 카메라 각도에 따라서 야기되는 characters의 변형 관점에서 취약하게 된다. 게다가, 그것은 백본 구조의 성능에 구속된다. (SSD를 사용하고 앵커 박스의 수와 크기에 따라 제한됨)
3. Methodology
주요 목적은 결국 natural 한 이미지를 각각의 개별 문자로 정확하기 국한하는 것이다. character 영역과 글자들 사이에서 affinity를 예측하기 위한 DNN을 훈련시키는 것이다. 그리고 이러한 것을 하고 싶지만 데이터가 없으니 weakly supervised 방법으로 필요한 데이터를 모으겠다고 한 것이다.

3.1. region score, 2. affinity score
뼈대는 VGG16 + Batch Normalization을 기반한 FCN을 썼다. Decoding Part에서는 low level features를 통합하기 위한 U-NET과 같은 Skip Connections을 가지고 있다고 한다. 마지막 결과물에는 2가지 채널이 있다.
3.2. Training
3.2.1 Ground Truth Label Generation
각 train 이미지에 대해, 우리는 region score에 대한 Ground Truth label과 character level bouding boxes의 affinity score를 생성한다. 우리는 픽셀 별로, region score, affinity score를 gaussian heatmap으로 인코딩한다. 이 heatmap representation은 엄격하게 bounded 되지 않은 ground truth 영역을 다룰 때 높은 신뢰성 때문에 Pose estimation 작업에도 사용한다고 한다.


Region Score Map 생성하기
1. 2차원 isotropic Gaussian map을 준비한다.
2. 이미지 내의 각 문자에 대해 경계상자를 그리고 해당 경계상자에 맞춰 가우시안 맵을 변형시킨다.
3. 변형된 가우시안 맵을 원본 이미지의 경계상자 좌표와 대응되는 위치에 해당하는 Label Map 좌표에 할당한다.
Affinity Score Map 생성하기
Character box에 대각선을 그엇을 때 생기는 위쪽 삼각형과 아래쪽 삼각형으로부터 각 중심점을 구할 수 있다.
하나의 word에 포함되는 인접한 두 character에 대해 삼각형 중심점을 이었을 때 만들어지는 사각형이 바로 Affinity box가 된다.

이렇게 제안된 ground truth 정의는 작은 receptive fields를 사용함에도 불구하고, 크거나 긴 text instance를 충분히 탐지할 수 있는 모델이 되게 한다. (반면에, box regression 같은 경우에는 이렇게 하려면, 큰 receptive field가 필요하다.) character-level detection은 전체 text instance 대신에 오로지 intra-character와 inter-character에 (character 내 + character 간) 초점을 맞추는 convolution filter를 가능하게 만든다.
3.2.2 Weakly-Supervised Learning


합성된 데이터셋들과 다르게 현재 데이터셋은 word level annotation을 가지고 있다. 그러므로 weakly supervised manner을 통해서 word level annotation으로부터 character box를 생성해야 한다. word-level annotations이 있는 리얼 이미지가 제공될 때, 학습된 interim model은 크롭된 단어 이미지의 character region score를 예측하여 character level 바운딩 박스를 생성한다.
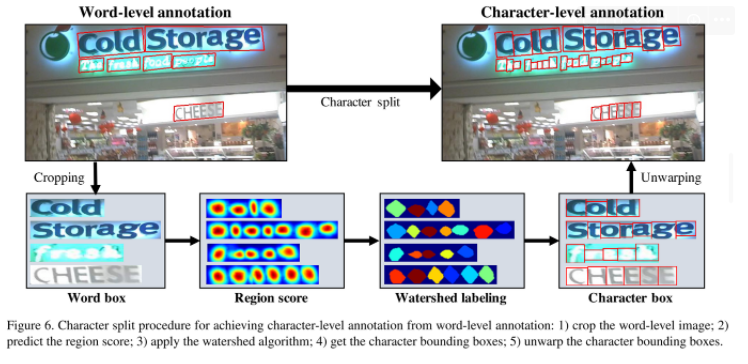
Characters로 쪼개는 과정을 다음과 같다.
- 실제 이미지로부터 word-level image를 cropped 한다.
- 지금까지 훈련된 모델로 region score를 예측한다.
- character 영영들을 쪼개기 위해 watershed algorithm을 사용한다.
- Region을 포함하는 character bounding box를 만든다. - character box의 좌표를 unwarping(뒤틀림이 없는) 과정을 거쳐 실제 이미지 좌표로 바꿔준다.
(=character box 좌표를 실제 이미지 좌표로 이동)

이 방법을 통해 얻은 Ground Truth는 Interim model에 의해 예측된 것으로 실제 정답과는 오차가 존재한다. 따라서 Pseudo-Ground Truth라 부른다. Interim model로 예측한 Character box를 통해 얻은 Pseudo-Ground Truth는 학습 시 모델의 예측 정확도에 악영향을 줄 수 있다. 따라서, 학습 과정에서는 Pseudo-Ground Truth의 confidence(신뢰도)를 반영하여 최적화한다. Confidence score는 각각의 Word Box: w 마다 다음과 같이 계산된다.

실제 단어의 길이와 Interim model에 의해 Split된 Character box 개수 사이의 오차 비율을 계산하는 것이다.

예를 들어, ‘COURSE’ 라는 단어(L(w)=6)의 Word Box를 Character Box로 분리하는 과정에서 5개의 Character Box가 예측되었다면 ‘COURSE’ Word box의 Confidence score는 5/6이 된다.

이미지의 각 Word-box에 대해 Confidence Score를 계산한 후 이 값들을 이용해 다음식을 만족하는 Confidence Map을 만든다.

synthetic data로 학습할 때 real ground truth를 확보하기 때문에 S_c(p) = 1 이 돼야 한다.
CRAFT 모델은 더 정확하게 character를 예측하고 confidence socre S_conf(w) 점점 향상되는 것을 확인했다고 한다.
만약 Confidence socre S_conf(W)가 0.5 아래라면, 추정된 character bounding boxes는 무시해야 한다. 왜냐하면 그들은 모델을 학습할 때 불안전한 효과를 주기 때문이다. Word Box를 단어 길이 L(w)로 등분한다. 그리고 Confidence Score는 0.5로 설정한다.
3.3. Inference
이제 추론 단계인데, 마지막 결과물은 word boxes 나 character box 같이 아니면 polygons와 같이 다양한 모양을 전달해준다. ICDAR 데이터 같은 경우 평가 protocol는 word level intersection-over-union(IoU)로 합니다 IoU는 면적이 얼마나 겹치는지, 따라서 여기서는 간단하지만 효과적인 후 처리 단계를 통해 예측된 Sr 및 Sa의 워드 레벨 경계 상자 QuadBox를 만드는 방법을 설명한다.
the bounding box를 찾는 post-processing는 다음과 같이 요약할 수 있다고 한다.
- 이미지를 덮는 the binary map(M) 0으로 초기화한다.
- 만약 S_r(p) > T_r or S_a(p) > T_a이라면, M(P)는 1로 합니다. 여기서 tau는 threshold이다.
- M에서 Connected Component Labelling(CCL) 수행된다.
- QuadBox는 레이블들의 각각에 상응하는 연결된 구성요소들을 아우로는 최소한의 면적으로 회전된 사각형을 찾음으로써 얻게 된다!
- OpenCV에서 제공되는 connectedComponents와 minAreaRect와 같다고 한다.
CRAFT의 이점
- 더 이상의 post-processing 방법이 필요하지 않다.
- (Non-Maximum Suppression(NMS))
- 왜냐하면, CCL로 분리된 단어 영역의 이미지 클럽을 가지고 있기 때문에, 단어의 경계 상자는 단순히 하나의 사각형으로 정의된다.
- 이와는 달리, 우리의 캐릭터 연결 프로세스는 명시적으로 텍스트 구성요소 사이의 관계를 검색하는 것에 의존하는 다른 링크 기반 방법과는 다른 픽셀 수준에서 수행된다.
- 효과적으로 curved text를 다루기 위해서 character region을 둘러싸는 Polygon을 만들 수 있다.
- scanning direction을 따라서 character 영역들의 지역적인 maxima line을 찾는다.(파란색 선)
- local maxima lenghts의 길이들은 최종 폴리곤 결과가 불균일해지는 것을 방지하기 위해 그중 최대 길이로 동일하게 설정된다.
- local maxima의 중앙점을 쭉 있는 라인을 center line이라 하고 여기선 노란색선이다.
- 그런 다음 빨간색 화살표로 표현되는 문자의 기울기 각도를 반영하기 위해 로컬 최대선을 중심선에 수직으로 회전시킨다.
- local maximal lines의 끝점들은 text polygon의 후보점들이 된다.
- text region을 완전히 덮기 위해서 local maxima lines이 움직인다. (초록색)
